What is even better than having a really fast web
server, framework, programming language that creates
your web page? Not having to create and load the page at all
because it's already there in a cache.
After working through this guide:
you will know that many different caches influence your web app:
HTTP caching
Fragment caching
ActiveRecord QueryCache
Caches inside the Database
you will be able to configure rails for caching
you will be able to measure if a change you made improved the performance of your rails app
The basic algorithm is very simple: is the data I need already in the cache?
then retrieve it from there. If not, retrieve the original data and store
it in the cache.
Given these numbers it makes sense to keep a local copy of data that
we might use again soon. Better to read it from ssd or memory the second
time we need it!
Caches have finite storage so items are periodically removed from storage.
This process is called cache eviction.
HTTP Caching is built into the HTTP protocol. There are several
headers in both the HTTP-request and HTTP-response that influence
if the browser will cache a resource for later and how long
it will keep the resource in the cache.
The Server can send the Cache-Control: header:
Cache-Control: no-store - The cache should not store anything about the client request or server response. A request is sent to the server and a full response is downloaded each and every time.
Cache-Control: no-cache - The cache will send the request to the origin server for validation before releasing a cached copy.
Cache-Control: public - that the response may be cached by any cache.
Cache-Control: private - the response is intended for a single user only and must not be stored by a shared cache. A private browser cache may store the response.
As we already discussed in the chapter on the asset pipeline
it is important to measure the performance of your app before you try to optimize anyhing.
In this chapter we will learn about new tools for measuring what happens on the server.
Let's start with a very general rule of thumb for performance:
We want the whole web page to load within a second. We expect to need about half of that (500ms) for loading extra assets like javascript files, css, images. We will set aside another 200ms for shipping data across the network, which leaves us with 300ms time to render out the first HTML document from our Rails App.
The Mini Profiler only measures the server side: the time spent in the rails app to generate
the webpage. So we need to compare the numbers Mini Profiler gives us to the
300ms threshold defined above.
We will use a portfolio site as an example app. All the screenshots
above already show this example app. You can study the original,
where all the caching is already implemented.
Fragement caching is a feature of the Rails Framework. Looking at
the views and partials that are rendered, you can mark some fragments
of the output to be cached for later.
To decide which fragments can be cached and which parts of
the view have to be computed anew every time you need to know
about the application.
You have to decide on a cache store. This store can be
any "key-value" store.
For production the simplest
method when using just one web server is in-memory.
# in the file config/environments/production.rb
require 'active_support/core_ext/numeric/bytes'
config.cache_store = :memory_store, { size: 64.megabytes }
When using
several web servers you need a cache store that can be shared between them
like memcached or redis.
In development, to get a quick impression of what is saved to the cache
it is helpful to use the file_store:
# in the file config/environments/development.rb
# config.cache_store = :memory_store
config.cache_store = :file_store, "#{Rails.root}/tmp/file_store"
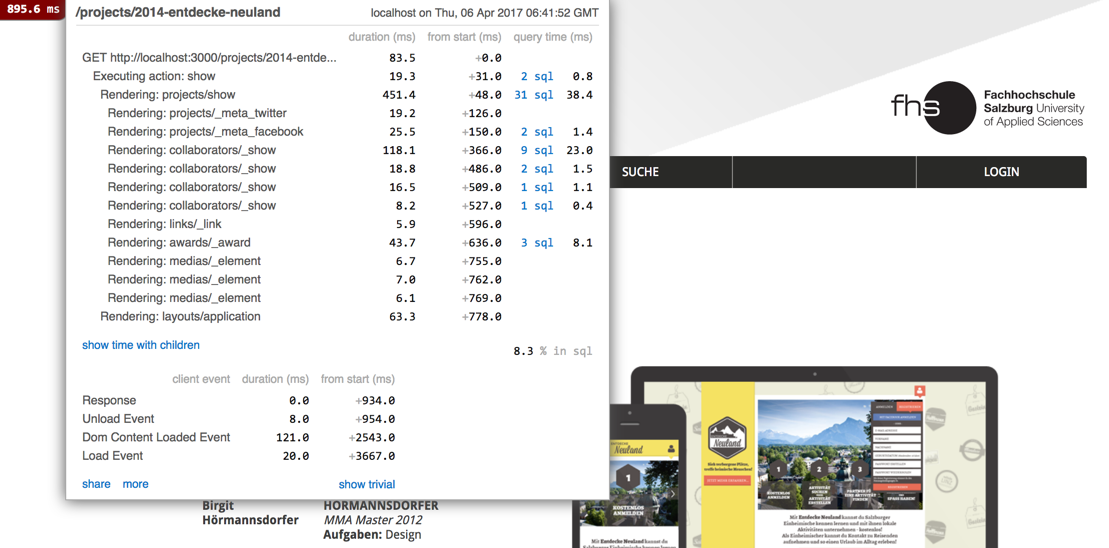
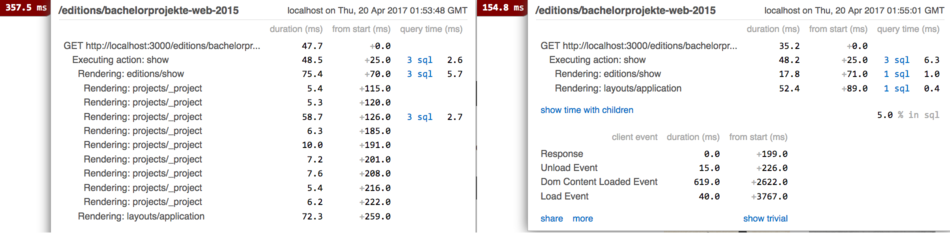
So what happens here? When the view is rendered for the first time,
it will be rendered normally and still take around 450ms.
In the log file you will see a message like this:
Write fragment views/projects/show:0db0955317bafa37cc34ffcb7567a8/projects/741679-20140722193808000000000 (1.1ms)
This shows the key that is used for the fragment.
The key depends
on both the object we specified (here @project), and on the view fragment.
The first part of the key the name of the view plus a hash of the view fragment inside the cache block.
After the colon you can see the class of the model, the id '741679', and the value of the updated_at attribute - in this example '20140722193808000000000'.
So if either the object or the view changes, a new key will be generated,
and nothing will be found in the cache. The view will be rendered from scratch.
The result is a string with 14716 bytes of html (too long to show here).
When using file_store you can also find the cache in the directory you specified.
A two level directory structure will be generated for the cache files,
for example:
$ ls tmp/file_store/*/*/*
tmp/file_store/5CD/A81/views%2Fprojects%2F2205-20170312162506000000000%2F0db0955317bafa37cc34ffcb7567a874
tmp/file_store/5D0/6A1/views%2Fprojects%2F2182-20170313205317000000000%2F0db0955317bafa37cc34ffcb7567a874
tmp/file_store/5D7/A81/views%2Fprojects%2F2208-20170321190926000000000%2F0db0955317bafa37cc34ffcb7567a874
tmp/file_store/5E6/091/views%2Fprojects%2F1679-20140722193808000000000%2F0db0955317bafa37cc34ffcb7567a874
Now let's check if the cache is really invalidated when the underlying model
changes. Load the project "Origin" in your web browser: http://localhost:3000/projects/2015-origin
In the rails console you can find the corresponding model, and change an attribute:
project = Project.find_by_title('Origin')
project.description = project.description + " and some new information"
project.save
Now reload the browser to make sure that a new version of the page is rendered.
Reload again to check if the new version is cached.
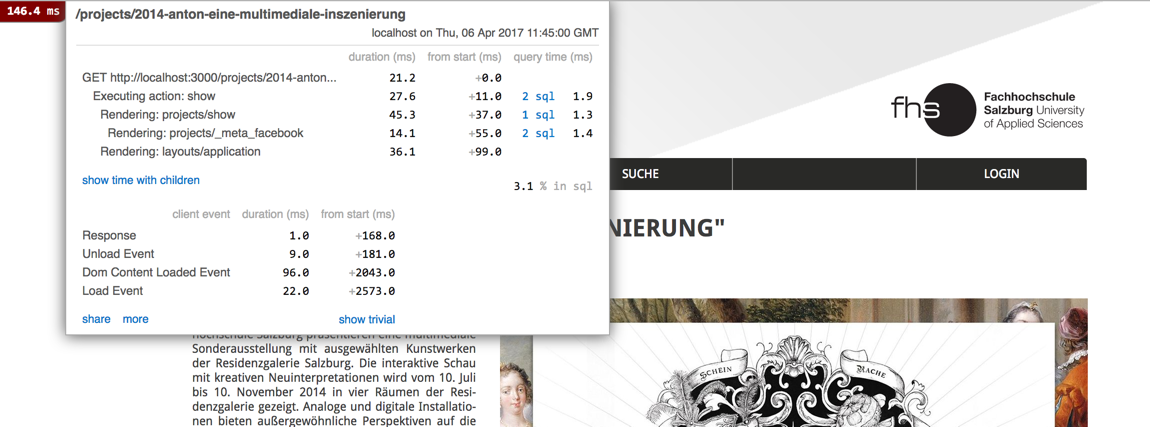
If you look at the original homepage
you’ll see that each department displays a "current featured project".
Caching the entire homepage won’t work if we want to keep this feature dynamic.
For example, when a department updates its featured project,
the homepage will still show the old version if the whole page is cached.
A better approach is to cache only the individual project display
instead of the whole homepage. This means caching at the level of
the projects/_project.html.erb partial, so updates are reflected dynamically.
This strategy works well, especially when the partial is reused in multiple places.
To generalize, think about an "activity stream" on a social media site.
The page looks different for every user and updates with each reload.
However, smaller fragments — like individual posts, photos, or videos —
can still be cached and reused efficiently across pages.
An unexpected side effect of caching the partial can be seen in the
edition view:
this view also uses the projects/_project partial, so it too will
profit from the caching.
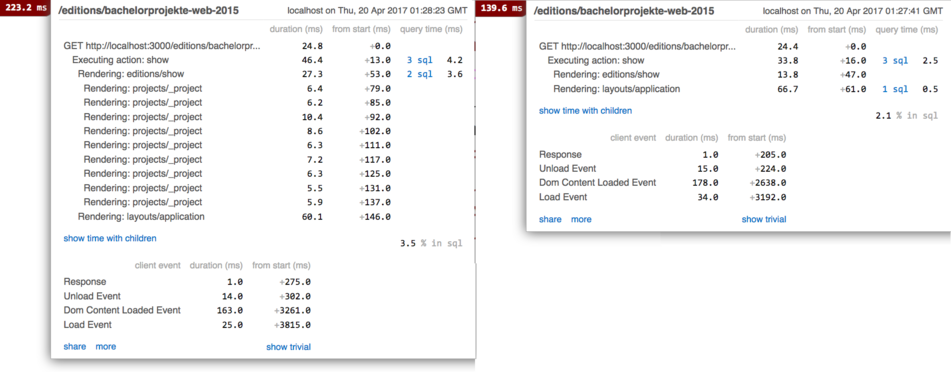
In the previous step we implemented caching for the projects/_project partial,
which is also used in the editions/show view. Now let's add caching to this
view also:
<% cache @edition do %>
...
<% end %>
This change will again speed up the display of the page:
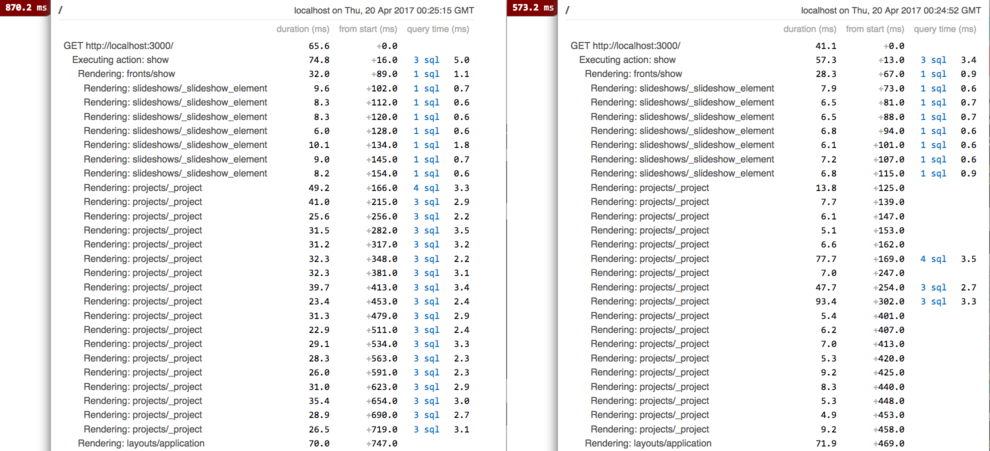
But now we have problem: if we change one of the projects
inside this edition, the cache for the partial would be recreated.
But this never gets triggered, because the cache for the
whole edition is still valid:
In the example below the title of one of the projects was changed:
You can see in rack-mini-profiler that only one of the
partials was recreated, all the other partials were loaded from cache.
The next time the same page was rendered the edition cache was reused.
Caching is really helpful for pages that are accessed a lot.
In our example app this might be true for the homepage and
maybe the editions. But there are hundreds of projects in the portfolio.
Each individual project page will only get very few hits.
Which means that chances are high that the page will not
already be in the cache when it is requested.
You can "warm up the cache" by automatically loading the most
important pages of your app after each deployment.
But caching cannot be the solution to all performance problems.
If you find that the backend framework causes a performance problem
you should be able to narrow down the problem and fix it using
different methods. You should be able to:
configure caching in development and production
use caching for fragments that depend on one or several objects
use caching with partials and collections
recognize russion doll caching and debug it if necessary
Accessing the database is significantly slower compared to the computations performed in Ruby code. Therefore, examining the database and the ORM used to interact with it could be a valuable step toward performance optimization.
Before you start working on the Database,
make sure to switch off caching in development:
# on the command line
$ rails dev:cache
Development mode is no longer being cached.
In config/environments/development.rb you can
set cache_classes to true, to get rid of extra sql requests.
But beware: now you have to restart the rails server after changing the source code!
# In the development environment your application's code is reloaded any time
# it changes. This slows down response time but is perfect for development
# since you don't have to restart the web server when you make code changes.
# config.cache_classes = false
config.cache_classes = true
If you find SHOW FULL FIELDS queries in your log file or in rack-mini-profiler,
you can ignore them. These
queries are used by activerecord to find out which attributes an
object has. In production these will only occur when the first
object of a type is loaded, so you can savely ignore them.
If you look into the log file logs/development.log you will
see all the SQL queries made to the database, and also some that
are not really sent to the database.
Started GET "/projects/2014-yokaisho" for ::1 at 2017-04-20 04:40:10 +0200
Processing by ProjectsController#show as HTML
Parameters: {"id"=>"2014-yokaisho"}
...
User Load (6.9ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 953 LIMIT 1
...
CACHE (0.1ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 953 LIMIT 1 [["id", 953]]
...
CACHE (0.0ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 953 LIMIT 1 [["id", 953]]
...
CACHE (0.1ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 953 LIMIT 1 [["id", 953]]
What we can see here is that the Data for user 953 was loaded four times.
Somewhere in our rails app we call User.find(953) or similar ActiveRecord
methods four times.
But only the first time a SQL requests is really sent to the database. Loading
the data from the database took 6.9 ms here.
The next three times the same user was loaded, it was loaded from the
ActiveRecord QueryCache, which only took 0.1ms or less.
The default behaviour is that rails loads each model only once for each
HTTP request.
For the next HTTP request the QueryCache is cleard. So one request-responce
cycle is the lifespan of the cached object.
When we query the database by id we will get a rapid response:
the primary key is always accessed through an index.
But in this app the main way of identifying a resource is
through a "friendly url". For example the project show action
is not accessed through the conventional route
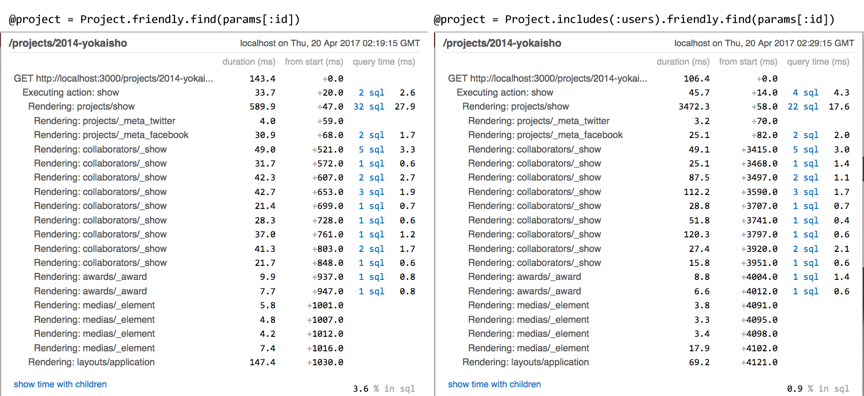
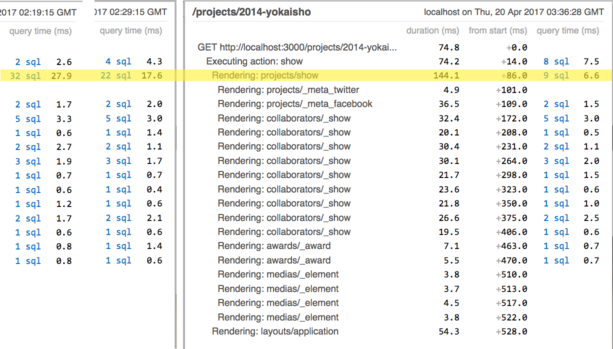
When analyzing the SQL queries generated by a Rails project, you’ll often encounter this common scenario: a one-to-many relationship, such as a project having many users. When displaying a project along with all its associated users, you may notice the n+1 query problem. This issue is present in our example app:
SELECT * FROM `projects` WHERE `slug` = '2014-yokaisho' ORDER BY `projects`.`id` ASC LIMIT 1
SELECT * FROM `projects_roles_users` WHERE `project_id` IN (1622)
SELECT * FROM `users` WHERE `id` = 1033 LIMIT 1
SELECT * FROM `users` WHERE `id` = 1018 LIMIT 1
SELECT * FROM `users` WHERE `id` = 901 LIMIT 1
SELECT * FROM `users` WHERE `id` = 938 LIMIT 1
SELECT * FROM `users` WHERE `id` = 945 LIMIT 1
SELECT * FROM `users` WHERE `id` = 977 LIMIT 1
SELECT * FROM `users` WHERE `id` = 953 LIMIT 1
SELECT * FROM `users` WHERE `id` = 652 LIMIT 1
SELECT * FROM `users` WHERE `id` = 940 LIMIT 1
Here 9 users belong to the project. They are loaded using 9 requests.
This is inefficient! If we were coding SQL by hand,
we could get the same data using one query with a join.
After this change we find a lot less SQL requests:
SELECT * FROM `projects` WHERE `slug` = '2014-yokaisho' ORDER BY `projects`.`id` ASC LIMIT 1
SELECT * FROM `projects_roles_users` WHERE `project_id` IN (1622)
SELECT * FROM `users` WHERE `id` IN (1033, 1018, 901, 938, 945, 977, 953, 652, 940)
The project model has associations not only
with the user model, but with many other models too.
If we include them all, we end up with a sizable reduction in SQL queries:
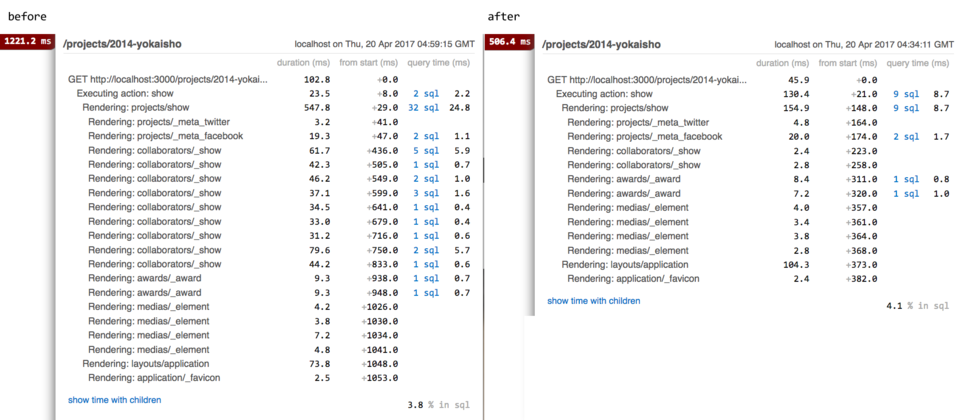
The last method of speeding up the database access is called a view. The word
view here has nothing to do with MVC in Rails, but is a technical term used in databases.
Let's look at a problem where a database view might be a solution:
in a previous version of the portfolio the display of a team member
was more elaborate:
The collaborator partial showed information
about one team member: the thumbnail, the name, their degree program(s)
and the role(s) they had in the project.
For the collaborators/_show partial a lot of SQL queries are created.
The information about the degree programs is found in 2 different tables:
To display "MMT Bachelor 2010, MMT Master 2014"
for Mr. Huber the helper method print_studycourses is used. We can try out this
helper method in the rails console:
> user = User.find(901)
User Load (0.5ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 901 LIMIT 1
> ApplicationController.helpers.print_studycourses(user)
Enrollment Load (0.5ms) SELECT `agegroups_studycourses_departments_users`.* FROM `agegroups_studycourses_departments_users` WHERE `agegroups_studycourses_departments_users`.`user_id` = 901
Studycourse Load (0.3ms) SELECT `studycourses`.* FROM `studycourses` WHERE `studycourses`.`id` = 3 LIMIT 1
Agegroup Load (0.4ms) SELECT `agegroups`.* FROM `agegroups` WHERE `agegroups`.`id` = 3 LIMIT 1
Studycourse Load (0.4ms) SELECT `studycourses`.* FROM `studycourses` WHERE `studycourses`.`id` = 5 LIMIT 1
Agegroup Load (0.4ms) SELECT `agegroups`.* FROM `agegroups` WHERE `agegroups`.`id` = 19 LIMIT 1
Here, data from three database tables is combined.
In the database console we can build a simple select statement with two
joins to get the same information:
mysql> SELECT user_id, concat(studycourses.name, ' ', year) AS name
FROM agegroups_studycourses_departments_users x
LEFT JOIN studycourses ON (x.studycourse_id=studycourses.id)
LEFT JOIN agegroups ON (x.agegroup_id=agegroups.id)
WHERE user_id=901;
+---------+-------------------+
| user_id | name |
+---------+-------------------+
| 901 | MMT Bachelor 2010 |
| 901 | MMT Master 2014 |
+---------+-------------------+
2 rows in set (0,01 sec)
Any Query can turned into a view by prepending it with CREATE VIEW ... AS.
mysql> CREATE VIEW degree_programs AS
SELECT user_id, concat(studycourses.name, ' ', year) AS name
FROM agegroups_studycourses_departments_users x
LEFT JOIN studycourses ON (x.studycourse_id=studycourses.id)
LEFT JOIN agegroups ON (x.agegroup_id=agegroups.id);
Query OK, 0 rows affected (0,06 sec)
After the view has been created, we can use degree_programs like a
table in the database. In fact, Ruby on Rails does not know that
this is not a "normal" table.
mysql> SELECT * from degree_programs WHERE user_id=901 ;
+---------+-------------------+
| user_id | name |
+---------+-------------------+
| 901 | MMT Bachelor 2010 |
| 901 | MMT Master 2014 |
+---------+-------------------+
2 rows in set (0,00 sec)
If we add a relationship from projects to degree_program (actually: three has_many through: steps to get from projects to collaborators,
and from collaborators to users, and from users to degree_programs), we can also include degree_programs in our
includes statement when loading the project:
To deploy the view to production, you need to create it with a migration.
Both the up and down methods of this migration use execute to run
SQL directly in the database.
class CreateViewDegreeProgram < ActiveRecord::Migration
def up
execute <<-SQL
CREATE VIEW degree_programs AS
SELECT user_id, concat(studycourses.name, ' ', year) AS name
FROM agegroups_studycourses_departments_users x
LEFT JOIN studycourses ON (x.studycourse_id=studycourses.id)
LEFT JOIN agegroups ON (x.agegroup_id=agegroups.id)
SQL
end
def down
execute 'DROP VIEW degree_programs'
end
end
In this case the view might be a first step towards refactoring
the database. We just have too many tables in the database that
are not really needed.
We can rewrite the rails app step by step to use only the new view,
and not the database tables it is supposed to replace. After we
have changed all the rails code, we can drop the view, and create
a table with the same data instead. Then we can drop the original tables
and are finished with the database refactoring.
In other cases you might use a view permanently: If you need both
the underlying, more complex data, and the simplified data in the view.
Reports with aggregated data, top 10 lists, queries that use
complex database expressions, or tables with a reduced set
of attributes would be good examples for using a view.
For data that is accessed a lot, but changes very seldom, you can
us a materialized view. In a normal view each access to the view
triggers the underlying sql requests. In a materialized view the
data is copied over to the view once. Like any other caching method
this needs more memory, but gives
faster access.
An ORM like ActiveRecord is a big help when writing a complex application.
But it cannot find the best SQL Query for every situation and it cannot improve the database.
As a developer you have to keep
an eye on your ORM, and check now and again if the SQL queries that the
ORM creates make sense and are efficient. You should
be aware of the QueryCache, know how to use it and how to break out of it
use indexes in the db for slow queries
recognize n+1 queries and avoid them by using includes
use view in the database to isolate complex sql and to add caching if needed